
【生成AI】生成AIで自分用のキャラを生成して遊びたい その6【LoRA】
前回の続き。

14日目
それでは本題のLatent Coupleを使っていく。
まずはインストール。
WebUIだけで完結するので丸投げしないで書いておきます。
WebUIを起動。
Extensionタブを開く。
Availableタブを開く。
Load From:を1回ぽちっと押す。
※Load From:の右側が空欄なら以下をLoad From:の右側に入れてぽちっと押す。
https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui-extensions/master/index.json
色々出てくるので中段のshowing typeの↓にある空欄に「Latent Couple」と入れて検索し、出てきたLatent Coupleの右側にあるインストールボタンを押す。

押した後、一覧から消えたらAvailableタブの左隣にあるInstalledタブを押し、でっかいApply and restart UIボタンを押す。
SettingタブのReload UIか、WebUIを再起動してtxt2imgの下の方にLatent Coupleが追加されてればインストール成功。
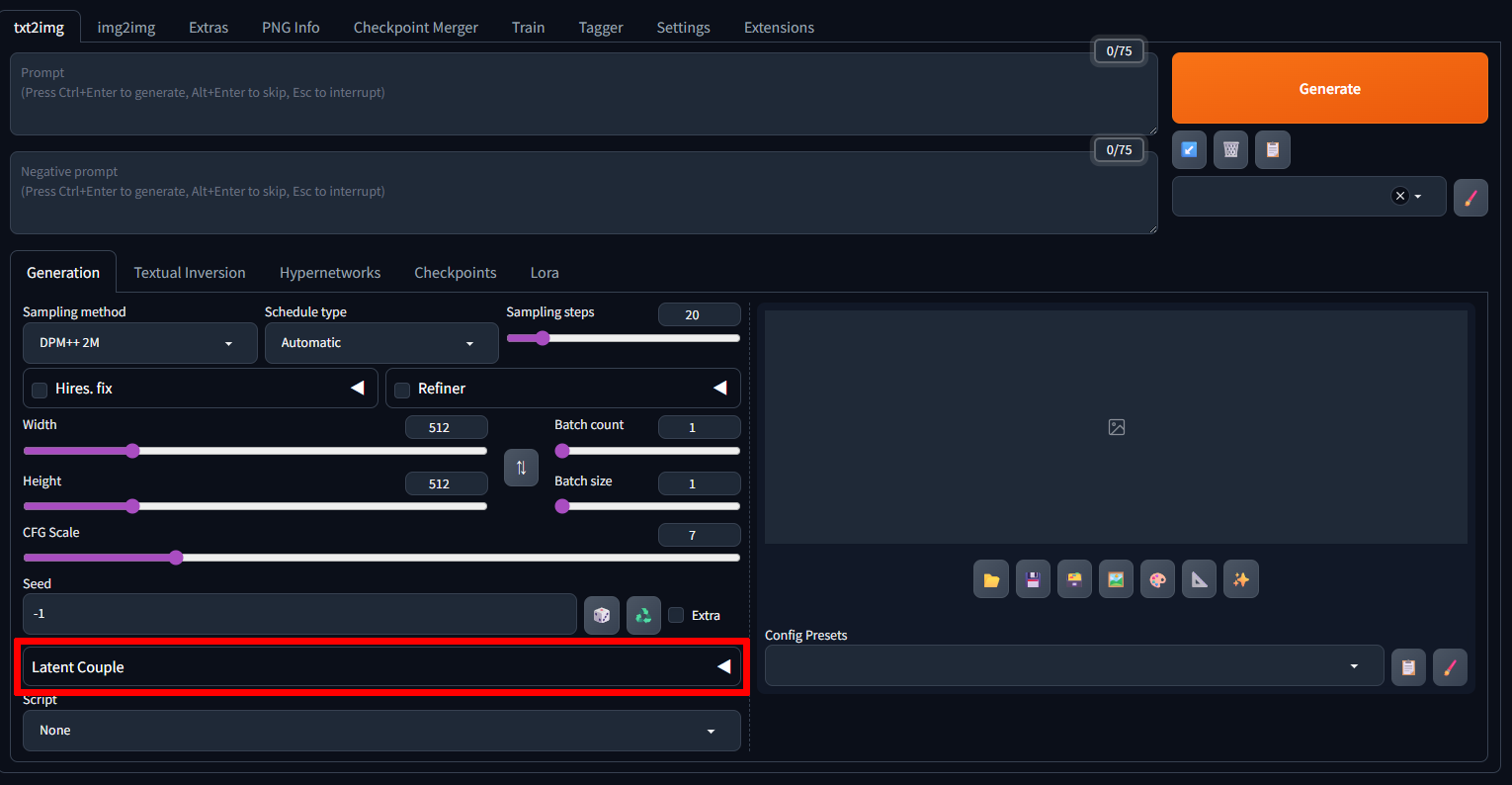
あとはこれを使って昨日のキャラを表示する。
まずは背景とか指定せずシンプルにやってみる。
先ほど追加されたLatent Coupleを開いてEnabledにチェック。(2人で左右分割ならデフォルトで大丈夫らしい)
プロンプトを、
全体プロンプト
AND 画面左Aキャラのプロンプト
AND 画面右Bキャラのプロンプト
という構文で書く。基本は全部書いて、2 girlsなどを強調しておく。
(背景、品質、小物などは重複して全部に書く。服の特徴やポーズなど、キャラに関することだけ別々に書く)
(masterpiece:1.4), (2 girls:1.2), look at viewer
AND
(masterpiece:1.4), <lora:A_chara:1>, (2 girls:1.2), (trigger_tagA), look at viewer Aキャラの服の特徴とか、ポーズとか。背景とか全体に関すること。
AND
(masterpiece:1.4), <lora:B_chara:1>, (2 girls:1.2), (trigger_tagB), look at viewer Bキャラの服の特徴とか、ポーズとか。背景とか全体に関すること
こんな感じで、出力。

一人はきちんと出るけど、もう一人がなんかうまく出ない。
調べてみるとLoRAを複数使うとデフォルトではうまくいかないらしい。
Composable Loraを併用するとうまくいくらしいけど、最新版に上手く対応できていないとかなんとか。
ので、一旦保留とし、違う拡張機能のRegional Prompterというのを使ってみることに。
インストールはLatent Coupleと同じでExtensionタブからRegional Prompterを検索してインストール。
基本はLatent Coupleと同じ感じで、プロンプトはANDの代わりにBREAKを使うだけ。
ささっと設定してれっつ出力。

う、う~ん……。
絵柄がチェックポイントと違う、1/2ぐらいで服飾が怪しくなる、生成時間も4倍以上になってしまう、といった結果に。
画面2分割の背景無し、ポーズ無しでこれなので、キャラ同士を近づけたりすると結構大変なのでは……?
調べるとControlNet Open Poseと組み合わせたり、色々方法があるみたいなので調べて試すを繰り返してみよう。明日。
15日目
色々調べた結果、当初のLatent CoupleとComposable Loraの組み合わせで行くことに。
Composable Loraは標準版(ExtensionのAvailableタブでおとしてくるやつ)ではなく、Git Hubのフォーク版を利用。
こちらのURL。
https://github.com/a2569875/stable-diffusion-webui-composable-lora
ページを少し下に行ったところのInstallationにインストール方法が書いてあるので、WebUI上でその通りにインストールする。
全体の情景に「森林・木漏れ日」だけ指定して2人を指定して出力。

少し怪しいけど、二人出力できる。絵柄や指定無視はRegional Prompterとどっこいぐらい。
出力時間も4倍ぐらいになるけど、その点は10倍とかにならなければとりあえずは許容範囲内とすることにして。
Regional Prompterとどっちが良いかと言われると……変わらんかもしれない。
とりあえず設定切り替えるのが面倒なので、このままさらに指示を追加する。
想定は「冒険者2人が暗い洞窟の中をランタンの光を頼りに探索する」みたいな感じ。
指示を日本語で書くと「洞窟の中で二人で手をつないで歩く。片方は光ったランタンとラックサックを所持。二人とも右を向く」という感じ。
とりあえず特に調べずプロンプトに入力。LoRAのウェイトは3Dモデル感が出てしまう時があるので0.7に調整。

人物の数指定は(2 girls:1.1)と指定していたが、フュージョンしてしまっている。
顔もぼやけてしまっているが、ランタンが光る、歩く、辺りは忠実。
ちなみに9枚で1時間かかった。出力した解像度は1024×1024(Hires,fixで解像度2倍化)。
1枚当たり7分弱。
で。
上記の結果を受けて再度、怪しい箇所に重みをつけたりして再出力。画面も明るいのでdarkness(暗闇)指定をする。
1枚だけ出力で確認するものの、不安定さがヤバく、調べたRedditのコメントでは複数改行は駄目、との記述があったのでその通りにする。
改行無し、ネガティブで1girl指定、単語単語を少し整形して、れっつ出力。

下半身アップが多い。あと中央にいることでちょうど半身合体しているキメラが生まれやすい。
ということで、下半身アップ(lower body)と中央に焦点が合う構図(centered composition)、をネガティブに入れて引き構図のwide shotも入れて再度出力。

駄目っぽい。下半身構図はトークンの境目(75区切りのアレ)が靴だったりするのかもしれない。
でもそもそも根本的になにか違うので調べたいところだけど、一枚生成するのに時間かかるからこれはつまり時間がかかるということです。
と、生成中にRedditやらなんやらで調べたら、複数キャラ生成についてのガイドをCIVITAIで発見したので、一旦今やってる作業を棚上げしてこれを精読して試してみようと思います。
こういう解決の方向性が見えない穴にハマった時、自分で解決するのはほぼ無理なのでまずは他人のやり方を模倣しましょう。明日頑張る。
16日目
なんかコレじゃない複数キャラ生成を、なんとかしたい奮闘記3日目。
ということで、前回のCIVITAIの記事を紐解いていく。
全体的には先日やったRegional Prompterの使い方解説っぽいので流し読み。
と、一つの気になった文章があったので引用。
As you can see, I used that LoRA in the common prompt, but with half of the original weight (1 -> 0.5). Divide by the amount of regions you use, so if you have 2 regions, do half of the original LoRA weight. The reason for this adjustment is that each region takes the value, and the overall image shouldn’t exceed a reasonable amount of LoRA weight.
ご覧の通り、共通プロンプトでLoRAを使用しましたが、重みは元の半分(1 -> 0.5)にしました。使用する領域の数で割り算してください。つまり、領域が2つある場合は、元のLoRA重みの半分を使用します。この調整を行う理由は、各領域に値が与えられ、画像全体のLoRA重みが適切な値を超えないようにするためです。
LoRAの重みって画像全体で合計1超えちゃいけないのか…。(素人丸出し感想)
いやでも確かにLoRAの崩れ方が以前あったような過度に学習してるかのようなモデルの寄せ方だったのに気付くべきだった合計値が1を超えたから元のLoRAを過度に表現しようとしてあのような破綻をしていたというのなら納得できる(早口)。
多分、これはどの拡張機能を使っても共通の話なので、Latent Coupleでも同じだと思われる。ちょっとやってみよう。
LoRAの重み合計を1以下にして、プロンプトも指示を削って75以内にして出力。複雑なのはダメよ、とガイドも言っているので。

出力。
顔の崩れは無い感じ。画面の中央ラインを超えるとキャラが混ざるけど、いい感じに左右に散らばれば見れる感じになった。
そして出力している間に読み終わった。
内容としてはそこまで変わったことはしておらず、使い方を詳しく丁寧に書いてくれている感じ。
途中途中で拾ったTipsがかなり役に立ったので、これを元に再挑戦…前に、再学習して服装などの特徴を全てLoRAに注ぎ込んでなるべくプロンプトを少なくしてみよう。
学習中…に時間になったのでまた明日。まーたーあーしーたー。(にんげんっていいな風)
思ったより大変で、検索しても基本簡単な触りだけ紹介記事が多いのはつまりはそういうことだったんだろうと少し察してしまうけど、とりあえず出来るところまでやってみる所存。
まて次回。
