【生成AI】生成AIで自分用のキャラを生成して遊びたい その5【LoRA】

前回の続き。
11日目
そういえば以前、Illustrious系の学習用LoRAチェックポイントがある、ということを聞いたのを思い出したので、その素材を使って学習をしてみることに。
意図しない画風の変化を軽減し、精度も改善します。
ということだそうです。れっつ学習。
学習も2パターン用意し、
ChatGPTがオススメの学習率5e-05 エポック3のやつと、
SDXL系学習時プリセットの8e-05 エポック4を試してみた。
学習は時間がかかるので待ち。
なんかこう、時間がかかる作業を一つ一つしらみつぶしに試していくのは、
ソフトウェア開発の単体テストにめっちゃ近いな…と思いつつ、残業がゆるかった時代のデスマーチ記憶がよみがえりそうになったのでフタをして待つ。
終わった。出力。
SDXL系学習時プリセット

ChatGPTオススメ

めっちゃ綺麗になってびびった。
学習の差でここまで出るとは。
とりあえず、プリセットの方は学習時間が長い分、細かいところで学習元を反映できている気がする。
特に縞の柄の入り方などの服の細部。(元画像は完全な横縞ではなく、少しパターンが違う)
過学習のような破綻も見られないので、今後学習するときはプリセットで良いかも。
昨日までの苦労がなんだったのかレベルだけど、一応タグの整理ができたという収穫はあったのでよしとします。 ヨシ!
ちなみにチェックポイントはntrMIXIllustriousXL_v40です。
では、戻ってゾンビのやつを出力テスト。

街中で銃を持つ、という指定は割と大丈夫なんだけど、

複数登場人物を指定するとおんなじ服着たクローン人間が精製される。
この画像ではsurrounded 3 zombieと指定したものの、ゾンビっぽい女の子と2Pカラーですらない同一人物が出てくる。
ChatGPTに聞きながら修正するも、上手くいかず断念。
タグの指定でなんとかなるような感じではない気もする……。
と、そういえば画面の左側、右側みたいな切り方で指定を分ける方法があるとかないとか聞いたことがあるので、
そういった、別の切り口からの解決方法が無いか探すのを明日の自分に託して就寝。
12日目
ゾンビを上手く出力する方法を考え、2つのパターンが合っているのではないか、と調べ至る。
一つ目は「Latent Couple」。
こちらはWebUIの拡張機能で、画面の領域を指定してそれぞれ出力できる、というもの。
前回言及した、画面の左側、右側みたいな切り方で指定を分ける方法、はコレ。
主役級を2人、3人並べる時に特に役に立つけど、今回のゾンビはいわゆるMOBなので、これでもできそうだけど、画面領域の指定が面倒そう。
で、二つ目はimg2imgの「Inpaint」機能。
これはWebUIのimg2imgタブにあるInpaintから行える機能で、画像を塗りつぶしてマスクをかけ、その範囲部分だけ再生成する、というもの。
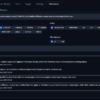
今回はこちらで、女の子ゾンビもどきたちを消去して再生成するのを試してみる。
修正する画像はこれ。

まずはぬりぬり行程。
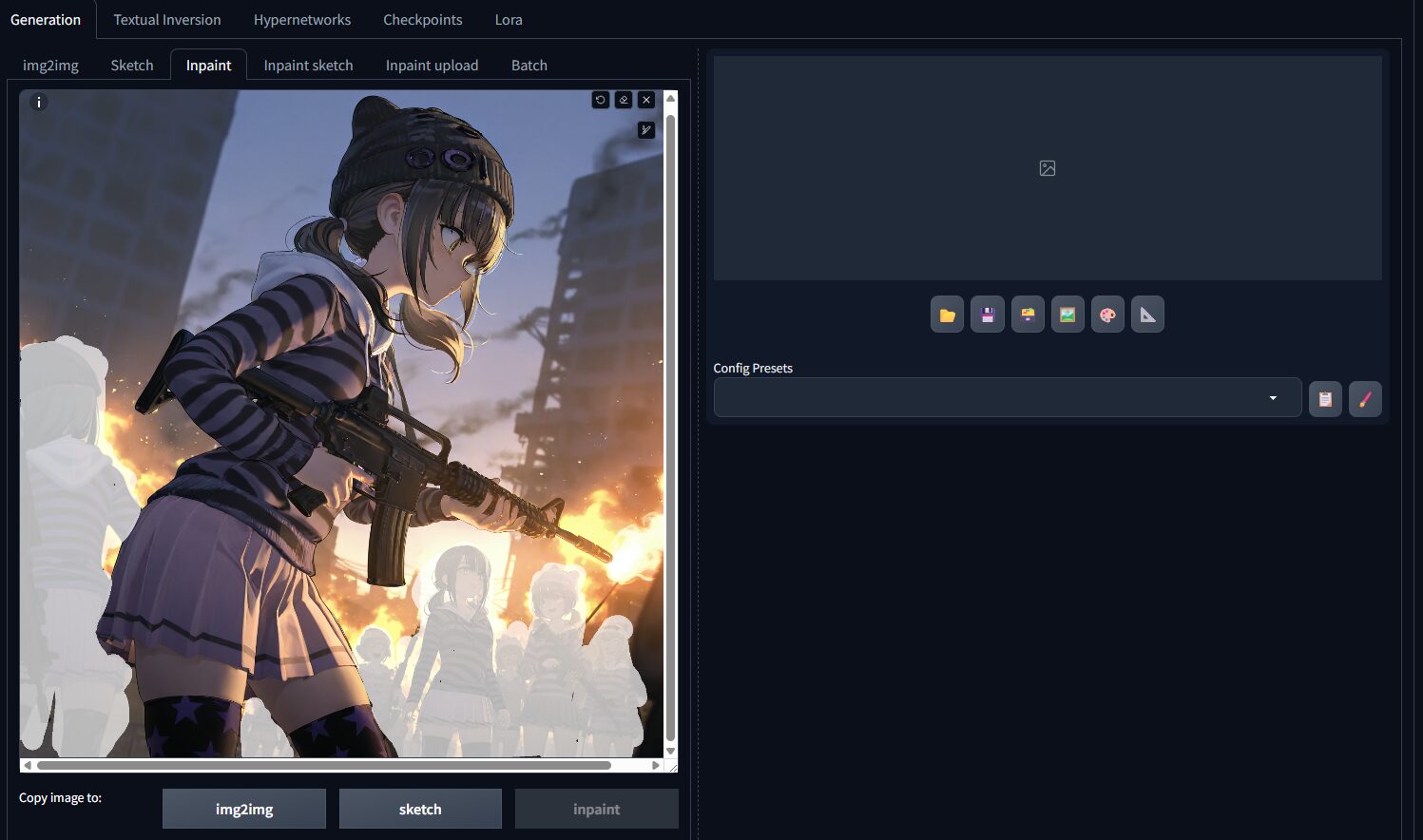
img2imgタブに行き、Inpaintを開いて画像をドロップすると、こんな感じで編集できるようになる。
ブラシでぬりぬりすると塗ったところが白くなり、 “その部分だけ” or “その部分以外” を指定して再生成できるようになる。
あとなんか色々設定あるけど、今回は触れないのでスルー。Sampling設定などはtxt2imgと一緒なので省略。
大量生成された女の子MOBゾンビを塗りつぶし、プロンプトを試す。
ここで入力するプロンプトは基本はtxt2imgと一緒。
プロンプトの影響部分はマスクした部分だけではなく画像全体なので、統一感を出すためにある程度元画像のプロンプトを入れる必要がある。
全く同じのを入力するとまあ同じのが出てしまうので、背景やクオリティ、ライティング辺りはいじらず、登場人物だけをいじる。
色々試行錯誤した結果、LoRAを外して1girl指定をしつつ、周りにゾンビがいる、という指定。
プロンプトはこんな感じ。
(masterpiece:1.4),
1girl , surrounded 5 realistic topless male zombies.
illuminated by moonlight, ruined construction site,
flying debris, burning cars
1行目はクオリティ指定、2行目は人物、3行目は背景、4行目は演出。LoRAタグは外す。
高品質で、女の子一人(ここはマスク外だけど、中央の人物がいることを指定して指示を理解させる)、
周囲に5人のリアル・上半身裸・男・ゾンビを指定。
文法的にはgirl surrounded byと繋げたほうが合ってるけど、文章よりも単語単語で指定したほうが上手く効くっぽい。
残りはこの画像を出力した指定と同じ。アサルトライフル関連はゾンビが持っちゃったりするので削除した。
で、こんな感じになる。

なかなか良いのではないでしょうか。
ついでに左手が6本現象になってるやつと、左側ゾンビが近すぎるので消えてもらう修正もかけてみる。
手については前回の手関連をネガティブプロンプトに全トッピング。1回だけ通ればヨシなので。
mutated hands, bad hands, poorly drawn hands, malformed hands
左ゾンビもぬりぬりして修正。
境目を馴染ませたいときはMask Blurという項目の数値をあげるとマスクした部分としてない部分の境界が自然になるようです。
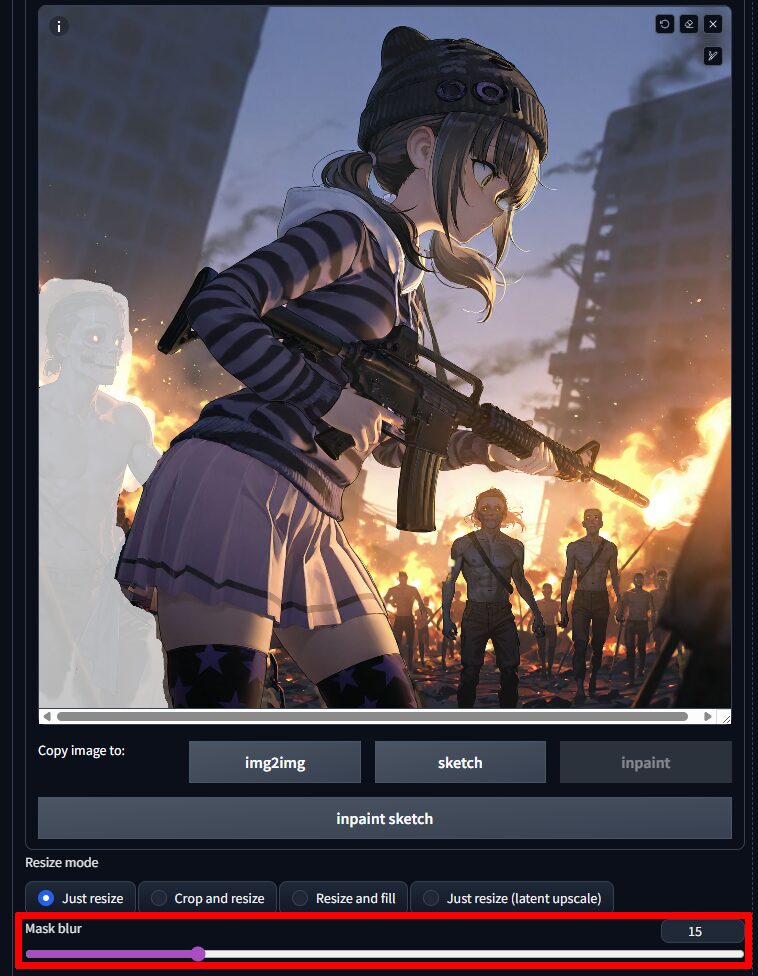
そして一応の完成形。

おぉ~。
細部がおかしかったり(M4とか)、ゾンビが謎のタスキをかけてたりと色々あるけど、それっぽいのが出たので満足。
最初はアクションシーンとか想定してたけど、疲れたのでここで妥協。終わり!
で。
調べたLatent Coupleの使い勝手も気になるし、一度使ってみて使用感を覚えるのは今後の役に立つだろう、
ということで。
次は「Latent Couple」を使った二人以上のキャラクターを一画像に収める、という課題に挑戦。
明日以降やります。
13日目
Latent Coupleでは二人以上のキャラクターが必要なので、せっかくだから学習素材&LoRA学習をしたキャラを二人用意することに。
今回のキャラクターはこの二人。
前回は銃器で現代日本風だったので、方向性を変えてファンタジー風にしてみた。


手順は以下。
1.素材用意(100~120枚程度)
2.WebUIのTaggerでタグ付け
3.BooruDatasetTagManagerで特徴だけ削除してトリガータグに特徴を詰め込む
4.Kohya_lora_trainerで学習 教師モデルはAnyIllustrious-XL プリセットはSDXLのキャラ用
上記をキャラ分やる。今回は2回。
そして出力したものがこちら。


髪の毛の色分けが今回あったので、それだけ書いておく。
1枚目の黒ピンク娘はヘアバンドから飛び出してる髪の毛(こういうのをエアインテークと呼ぶらしい)が白なので、エアインテークに白指定、
ロングヘアーの末端近くで結わったような髪型はlow-tiedで指定できる、らしい。元の金髪も併せて髪の毛を指定するとこんな感じ。
pale blond hair, all white air intake, low-tied long hair
本当はトリガータグに入って欲しかったけど、複雑なのか抽出されなかった。
(追加する方法があるらしいけど、面倒なので今回はパス。もっとたくさんそういうのが出てきたら考えます)
all whiteにしてるのはall指定がないと白くなるのが毛先か毛の中ほどまでか全体かがランダムになってしまうため、全体指定にしてる。allが正しいのかは分からない。
2枚目のノースリーブ白茶娘は毛先の色が黒色なので、それを指定。
プロンプトで指定するとこんな感じ。
white hair with black tips
△△ hair with 〇〇 tips
で、△△が全体の髪色、〇〇が毛先の色指定となる。
んで。
実は2枚目のキャラは元画像ではいわゆる「冒険者が数日間旅をするときに背負うバックパック」みたいなモノも持たせている。
画像はこれ。

15枚ほど学習データに入れておいたので、これも呼び出せるか試してみる。
…色々試した結果、上手く出てこない。
恐らく素材が足りないのが一番の原因だと思われる。
バックパックなど色々指定してみるが、一番それっぽい「冒険者のバックパック(リュックサック)」は
rucksack
ラックサック、が一番近いかも。
ダンジョン飯のライオスとかが背負ってる、寝袋が上に乗ってる大型のバックパックね。
現実でもそういうタイプをラックサックと呼ぶらしい。豆知識が増えた。
実際にrucksackのみ付けて出力するとこんな感じ。

「冒険者のバックパックです」って言うには縫製技術が素晴らしすぎる感じはあるけど「私のファンタジーでは紡績業が産業革命してるんだよ」で通せば大丈夫。
ということで、キャラがそろったのでこれをもとに二人のキャラクターが映ったファンタジーっぽい画像を作ってみる。明日。
次回はLatent Coupleを使ってみる予定です。