
【生成AI】生成AIで自分用のキャラを生成して遊びたい その1【LoRA】
画像生成AIに手を出してみました。その備忘録と日記を兼ねたモノ。
ゴールは「3Dキャラメイクゲーで作ったキャラを生成AIに覚えさせて安定して出力する」こと。
建前は「AI技術を体系的に学び、生成AI否定・擁護派両方の意見を理解できるようにする」こと。
建前がそれっぽいのは怖い世の中対策です。
では初日~三日目の軌跡。
初日
まずはAIの生成環境について。
Webブラウザ上やスマートフォンアプリで利用できる形態もあるが、出力数に上限があったり、ロゴマークが入ったり、モデルや生成物に制限があるものがあるので、ローカル環境ででき、比較的自由度の高い「Stable Diffusion」のローカル環境構築を選択。
それとは別に、色々触った感じ、現状(2025/11現在)で最も初心者に向いているのはOpenAIのSoraだと思われる。
Sora2は動画、旧版Soraは画像を生成することができ、両方とも文章(日本語)でのプロンプト指示ができるため、かなり直観的でわかりやすい上にクオリティが高く破綻が(他と比べて)少ない。
これから生成AIを初めて触ります! って人は全部これでいいと思います。
リンクhttps://sora.chatgpt.com/explore
動画が利用できるSora2はブラウザ版だと招待コードが必要。旧版Soraはブラウザでも招待コード不要。(画像のみ)
スマートフォンアプリ版だとどちらも招待コードは不要。(以前はどちらも必須だったが、11月に入ったあたりでアプリ版の招待コードが不要になった模様)
スマートフォンアプリ版でアカウントを作り、招待コードを貰ってブラウザ版に共有するだけで両方で利用可能なので、SNSで怪しい招待コード配る人には話しかけないように。
で、話を戻して。
ローカル環境構築について調べれば大量のnote記事が出てくるのでそれを参考に。
私は3Dキャラメイクで作ったキャラを安定して生成したいので、追加でLoRAを設定できる環境を構築。
以下のnoteが非常に参考になりました。ありがとうございます。

初日はせっせと環境を構築して終了。
「train_network.pyがみつかりません」が簡易インストールしても消えなかったが、これはインストールしたsd-scriptsフォルダの置く位置がおかしかったため、フォルダを移動したら解決した。
それ以外はそれなりに順調に行ったので特に書くこともなく。
LoRAで学習させたキャラはこれ。

某ゲームでつくったやつです。
顔のショット、全身のショット、背面、側面、表情差分などなど。背景は透過PNG。とりあえず20枚程度でお試し。
初日の生成物一覧はこんな感じ。
モデルはillustriousXL11_v11。
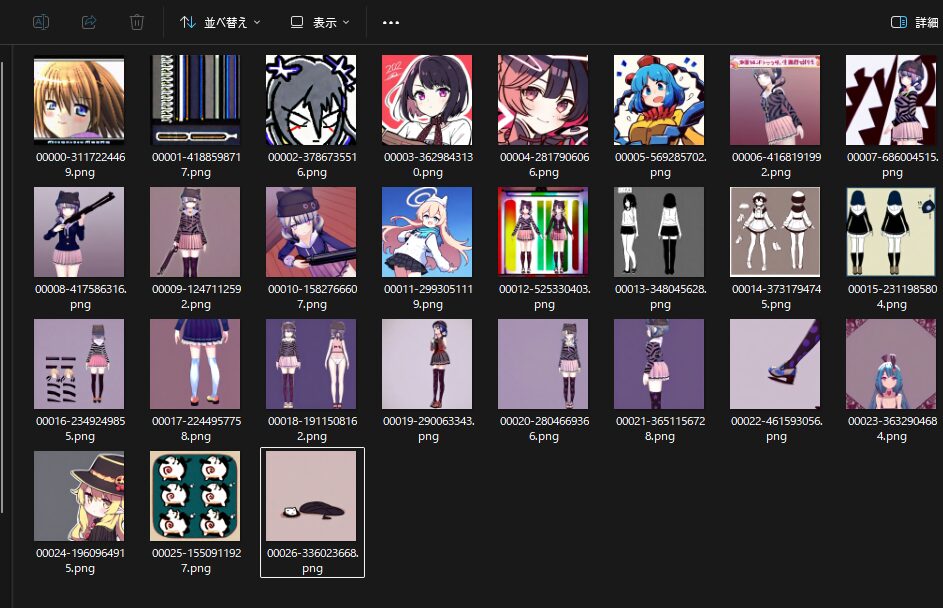
うーん。カオス。
LoRA指定を入れたり入れなかったり、プロンプトを調整してみたり。特に2枚目はなにを持って出力されたんだろうか……。
指定を外すとどこかで見たそれっぽいキャラが出ることは出る。
何枚かLoRAの影響を与えてるものもみられるけど、拡大すると目が崩れてたり手がおかしかったりする。

目がモザイクかけられてる。手がピンとしているのは、そういう画像を用意してしまったため。
3Dでの自然なポーズは2Dでの自然なポーズとはならないという、当たり前のことを再認識しました。
二日目
明けて、また夜。
せっせとWebUIを起動し、プロンプト入力画面を前に前日の反省から開始。
とにかく、LoRAを設定した際の画像がダメすぎる。ということで、学習素材の選定から開始。
素材を20枚から100枚にして再学習。また、プロンプトでLoRAの重みが強すぎるとLoRAの影響が強くなりすぎるようなのでウェイトを調整。
<lora:lora_data:1>
↑の1の部分。色々調べると0.6~0.75辺りがおすすめらしい。
それでプロンプトも試行錯誤しながら出力。
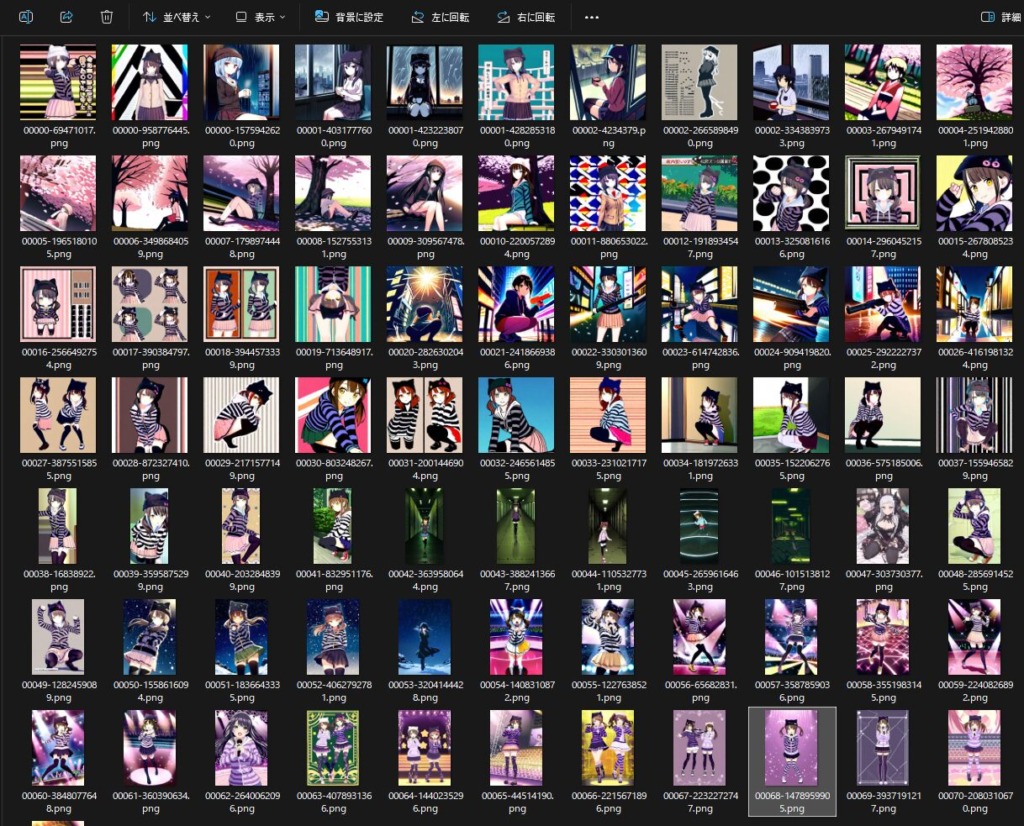
昨日よりはそれっぽい画像が出るようになった。
(後半はアイドルのように出力するようプロンプトを組んでます)
一番最後のプロンプトは
ポジティブ:
1girl, twintails, cat hat, brown hair, yellow eyes, bangs,purple striped hoodie, pleats skirt,star pattern thighhighs, anime style illustration, cell shading, warm lighting, sunset glow, backlight, vivid colors, strong shadows, clean lineart, dynamic lighting, detailed hair and eyesネガティブ:
(low quality, blurry, bad anatomy)
で出力…ではないかも、ちょっと違うけどまあ大体一緒。
ポジティブの中にLoRAで学習させた容姿の単語は入れないほうが良いとかあったけど、そこらへんの理解が浅いのでがっつり指定してます。(明日以降の自分がきっと理解してくれる)
![]()
原型をとどめつつ、プロンプトの指示に従ってくれているものの、なんかのっぺりしてる……。
もっとこう、巷で見る生成AI画像は綺麗というか、陰影がはっきりしているんだけど何が違うんだろう…と調べて悩んだ結果、chatGPTに聞きました。
色々問答をした結果、モデルによる特性なのでは? と思って聞くとこんな答えが。
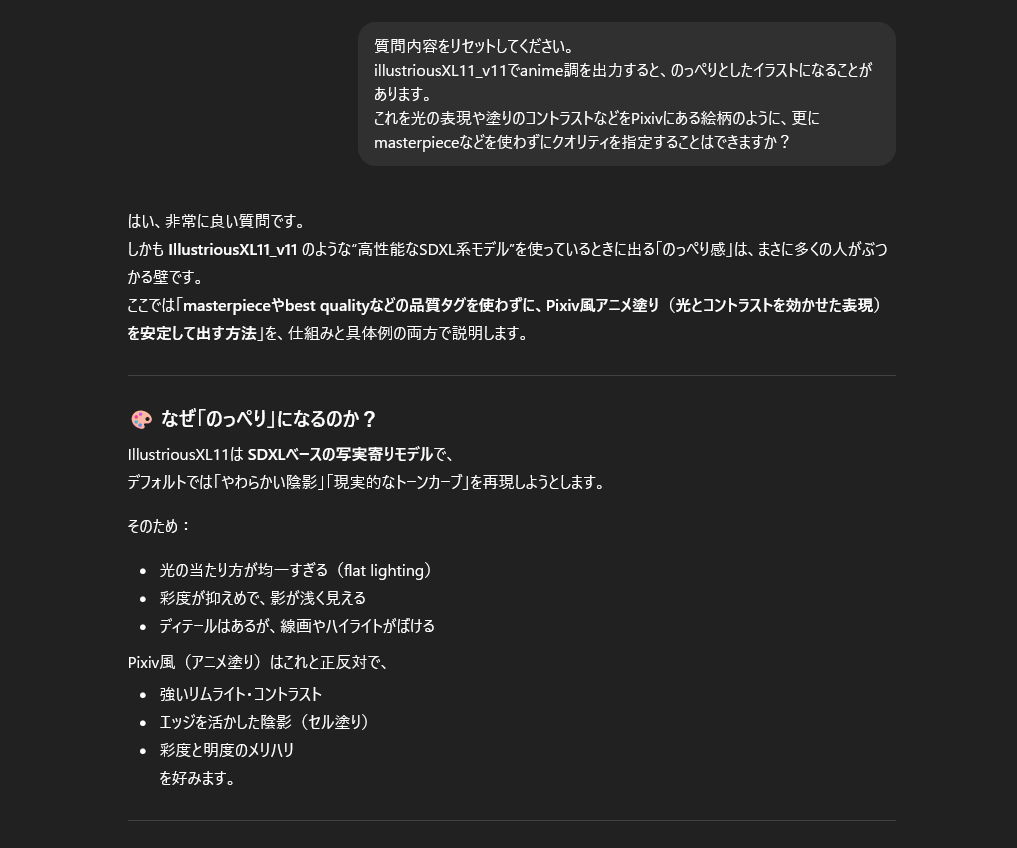
ということで、次回はモデル(正確にはチェックポイントと呼ぶらしい)の変更をしてみよう、と思ったところで時間になり就寝。
3日目
ここでモデルとLoRA、AI生成ソフトの関係について少しこんがらがったので一旦まとめる。
色々調べた結果……。
illustriousXL11_v11などはチェックポイントと呼ばれ、Stable Diffusion(SDXL)などのモデルを補完する形で使用される。
LoRAはそこに更に補完させる追加学習素材(追加モジュールのようなもの)。
Stable Diffusionはあくまでも学習方法、学習した素材をどういうアルゴリズムで生成するかを決めるもので、生成物(=絵柄やタッチ)そのものはチェックポイントに大きく依存する。
という認識に落ち着いた。正確かどうかはともかく、大きく間違っていることはなさそう。
で。
のっぺり絵柄はチェックポイントによる影響が大きいと分かったため、チェックポイントの選定に映ることに。
色々試してみる……けど、チェックポイントの試行錯誤、LoRAの生成で割と時間がかかるので今日はここで終了。


99mixで出力してみたもの。生成速度はめっちゃはやいですね。モデルは変わっておらず、illustriousXL11_v11の半分の容量なので、そこが関係しているんでしょう。
これはSD1.5系だから速い、という理解かな。
手が変なのは多分学習素材がよろしくないからです。
とはいえ、特徴を捉えつつイラストを生成できているように感じる。
また、今回は生成パラメータを色々と調整。
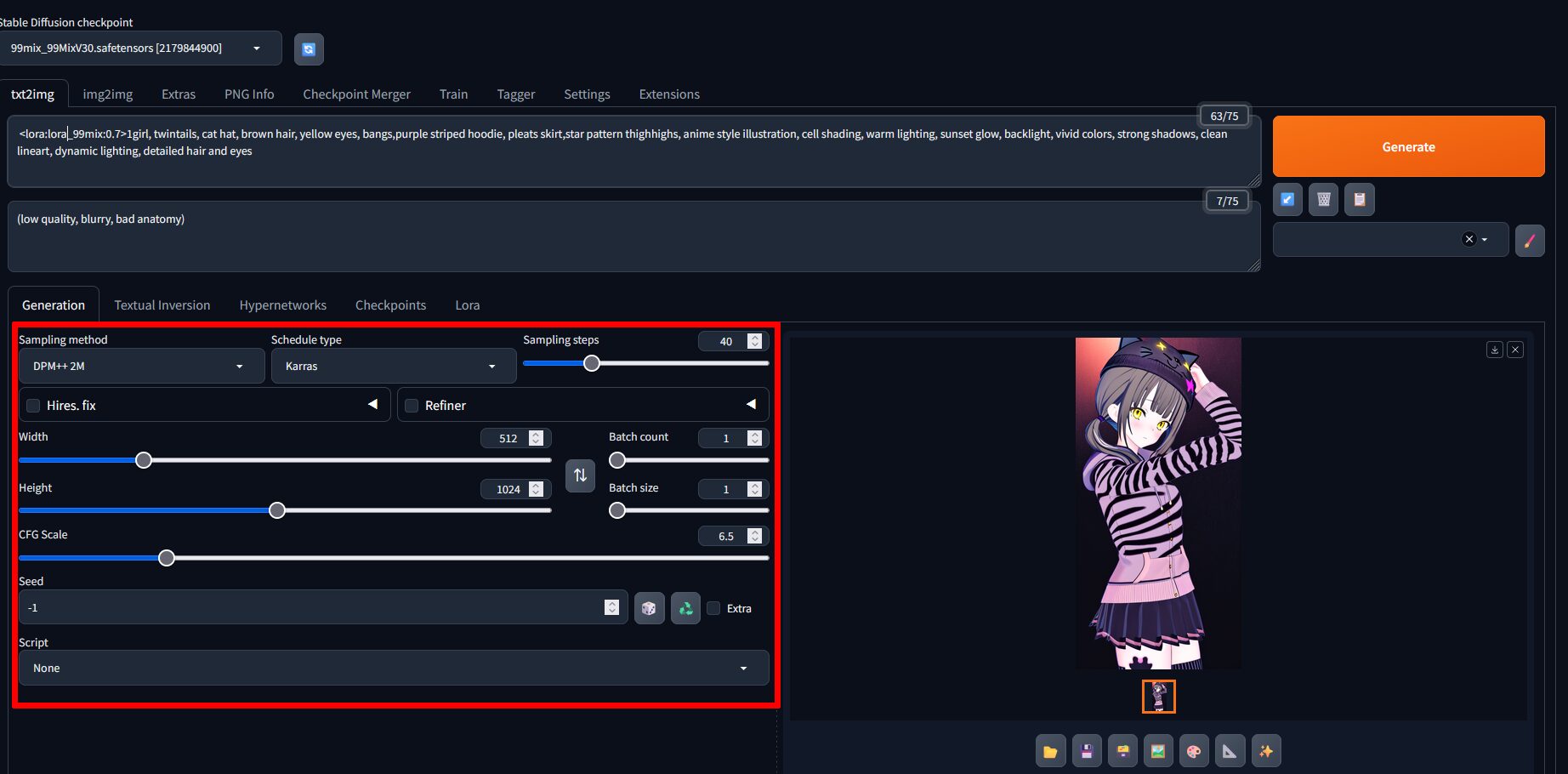
赤枠の部分。
デフォルトよりは変更したほうが良いかも。
DPM++2M & Karrasの組み合わせが速度、品質で安定している模様。
各内容はChatGPTくんがまとめてくれたので貼っておきますね。
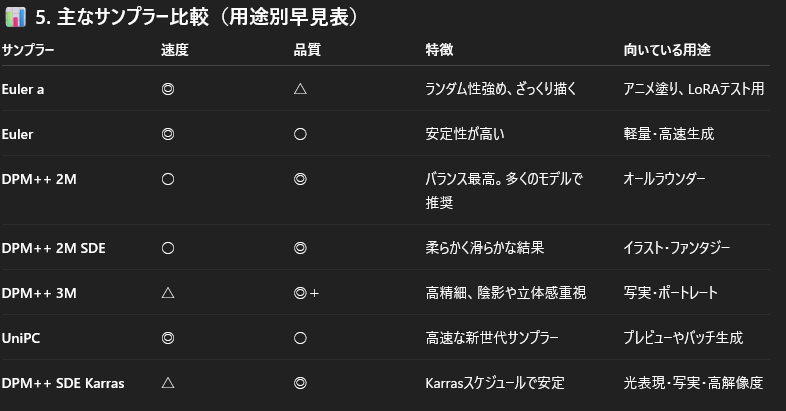

Width,Heightはそのまま横縦、CFG Scaleはプロンプトの影響力を決定し、数字を大きくするとプロンプト通り、小さくするとプロンプトの影響が弱まる。
Batch~は一度の生成で何枚生成するかの項目。
Seedは-1以外を設定しておくと、同じような画像を生成できるようになるらしい。(まだ試してないのでわからない)
以上。
次回は引き続きチェックポイントの選定と、学習素材(特にタグ関連や素材比率だと思われる)の修正になりそう。
第2回はこちら。
